Replicate
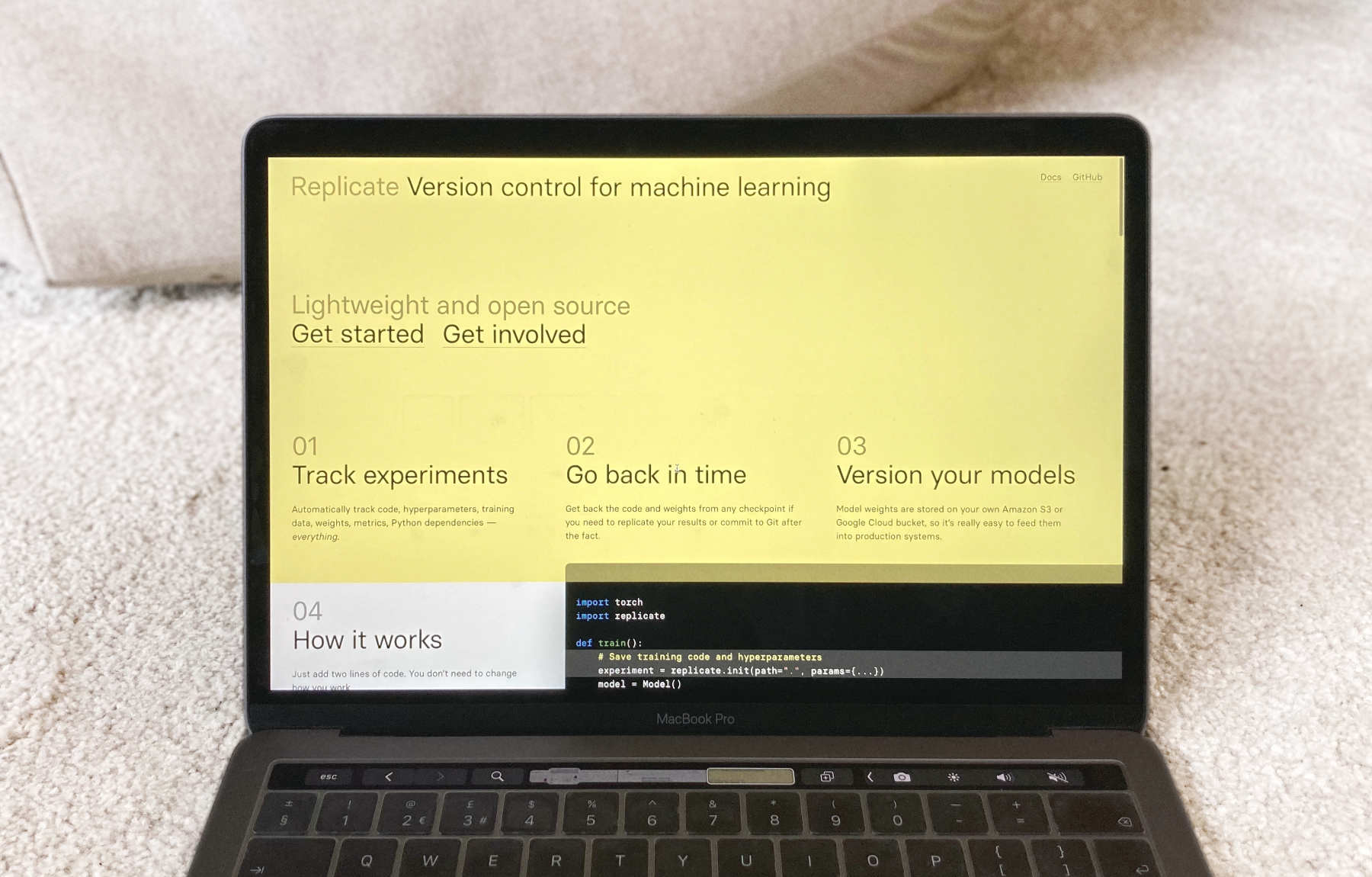
Over the last couple of months I’ve been helping Andreas and Ben with their new project, Replicate.
If you weren’t working in software before widespread, free-to-access version control it’s hard to express how differently things worked then. So much of the extreme programming stuff we take for granted like remote collaboration, iterative design, test driven development, a/b testing, public contribution to open-source, were almost impossible due to how time-consuming and unwieldy it was to explore, analyse and experiment with code over time. Software was chaos, and having only worked in it for a few years before Git took off, I’ll never take version control for granted!
When Andreas and Ben chatted to me about their research, and explained that version control isn’t freely available for machine learning I was surprised – my whole understanding of the industry needed recalibrating for a minute. You can sort of use Git, but making commits for every part of the decision tree is clunky. And there are some super-expensive proprietry enterprise packages available, but there isn’t a standard like Git which everyone can access. And without everybody being able to access the tool, there’s no way for you encourage everyone to adopt modern development practices the tool enables. Instead we end up with these AI black box systems, indistinguishable from magic.
As an aside – I’m not a tech ethics specialist but it’s definitely been part of my responsibilities in previous roles to keep on top of the debates and controversies around machine learning and AI. I’ve read a lot of the books, blog posts and criticisms of these technologies, been to a few meetups and stuff. In all of that, I’ve never heard anyone mention that these technologies don’t have the basic tooling we would expect in order for them to operate in the way we expect modern, transparent software products to behave. Instead it’s all conspiracy theories or demands for speculative features that can’t be built. IMO there’s a broader lesson about the basic technical literacy of the criticism and debates around our industry here that I’m going be unpicking for a while.
Back to the point, Replicate launched into public beta yesterday. It’s a simple, lightweight and open source command line tool that records your machine learning experiments. That makes it easier to poke around in your experiments in order to understand what they actually did. You can run it locally or on cloud services, it’s compatible with pretty much anything, and you can analyse the results in a notebook.
If that sounds like something you might be interested in, check it out here.
If you want to chat more about stuff like this, send me an email or get in touch on Twitter.
You can pretend it's 2005 and subscribe to my RSS feed